Language-Mediated, Object-Centric Representation Learning
1Stanford University
2MIT CSAIL
3Harvard University
* and † indicate equal contribution
Abstract
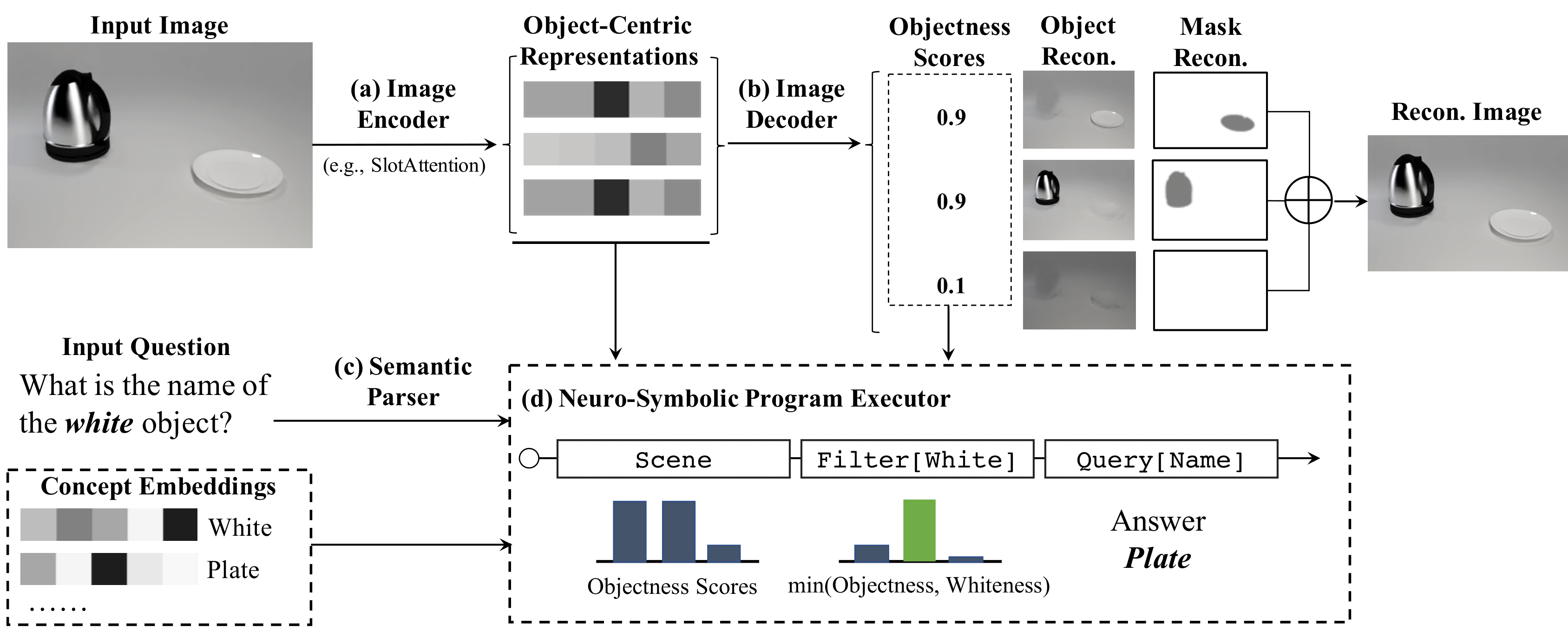
We present Language-mediated, Object-centric Representation Learning (LORL), a paradigm for learning disentangled, object-centric scene representations from vision and language. LORL builds upon recent advances in unsupervised object segmentation, notably MONet and Slot Attention. While these algorithms learn an object-centric representation just by reconstructing the input image, LORL enables them to further learn to associate the learned representations to concepts, i.e., words for object categories, properties, and spatial relationships, from language input. These object-centric concepts derived from language facilitate the learning of object-centric representations. LORL can be integrated with various unsupervised segmentation algorithms that are language-agnostic. Experiments show that the integration of LORL consistently improves the object segmentation performance of MONet and Slot Attention on two datasets via the help of language. We also show that concepts learned by LORL, in conjunction with segmentation algorithms such as MONet, aid downstream tasks such as referring expression comprehension.
Motivation
Two illustrative cases of Language-mediated, Object-centric Representation Learning. Different colors in the segmentation masks indicate individual objects recognized by the model. LORL can learn from visual and language inputs to associate various concepts: black, pan, leg with the visual appearance of individual objects. Furthermore, language provides cues about how an input scene should be segmented into individual objects: (a) segmenting the frying pan and its handle into two parts yields an incorrect answer to the question (Segmentation II); (b) an incorrect parsing of the chair image makes the counting result wrong (Segmentation II)